

AIGC对哪类影视从业者影响最大?影视幕后领域大佬这样回答

当下,AIGC的研究成果与观点瞬息更迭。当读者阅览此篇稿件之际,或许其中的部分内容已然过时,甚或已被证伪。于此,我力图以影视工作者能够领会的言辞,结合近三年整理的AI知识图谱笔记,阐述自身对于AI的观测与思索。
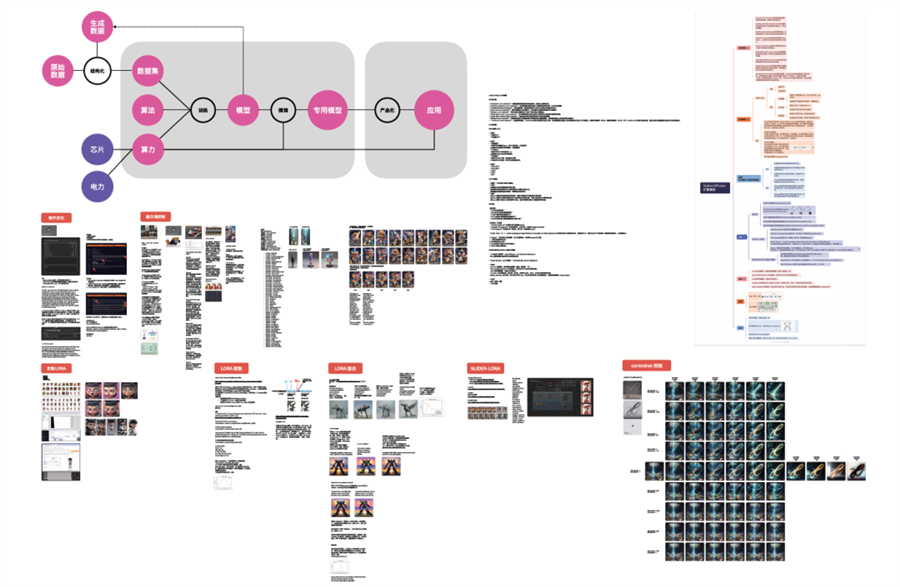
AI知识图谱 (局部)
AI发展至今,众人对其态度各异,或喜爱、或厌恶、或漠然,此乃基于我们所接触到的诸如PPT上的AI、工作中的AI、生活中的AI、他人所述的AI等各类不同AI所产生的直觉反应。
作为影视行业的从业者,我目前对于AI的态度是“现在拥抱,未来恐惧”,因为现阶段的AI属性是生产力工具,是我们的助手。我们担心的是未来AI可能以高级的方式对很多行业降维打击。
举个例子,现在有AI绘图、自动剪辑、生成视频等,但是为了做出媲美专业级品质的内容,这些工具变得越来越复杂,只有专业的人有能力掌握,又回到了专业的人用专业的工具做专业的事,所以我们要拥抱。而未来AI可能不需要学习制作电影,而是通过生物接口直接介入我们的神经系统,创造全新的体验,人类不再需要电影。
这里有个过渡产品就是目前的AR眼镜,头部大厂为了在几平方厘米的镜片上呈现更真实的影像豪掷重金,但目前依然没有出现现象级产品。所以未来AR产品的形态可能不是眼镜,而是脑机接口,这就是AI降维打击基础。我对未来的恐惧来自我们神经有可能被AI入侵,当然也不排除碳基生命永远无法转变为硅基生命,大家各自安好。
作为在影视后期领域工作二十年的老兵,在2021年10月开始关注AI绘画技术,并在同年11月与合作团队共同策划创办沸铜数字艺术展,共举办3届,1200位创作者参与,展出5800多件作品,当时征集到数百件AI绘画代表作品,通过研究这些作品,以及与这些AI创作者的持续探讨,让我对AI技术认知在不停地重建。
Q 为什么现在的模型越来越大?
这个问题需要简单梳理一下AI的技术路线。AIGC融合了机器学习、自然语言处理、计算机视觉等尖端技术。AI的两大驱动力是信息技术和数据。
一方面,算法的发展先慢后快,最早1951年出现的自然语义理解算法N-gram,到2016年后Transformer确立自然语言处理的江湖地位之后,计算机视觉CV、自然语言处理NLP、多模态处理算法VL等技术开始快速发展,算法发展的背后是计算机算力的巨大提升。
另一方面,从2000年互联网技术爆发,到2010年之后移动互联网普及,为现代AIGC的发展提供强大的数据支持。当2009年李飞飞教授发表Image Net论文提出通过更多数据就能改进算法时,图像识别大赛PASCALVOC引入Image Net成为衡量分类算法在复杂图像数据集上的表现的一个基准,参与大赛的算法经过Image Net数据集训练后表现更好,自此业界开始信仰使用更大的数据集叠加更强的算力就可以训练出更优质的模型,从而解决更复杂的问题,以期实现AGI通用人工智能。自此让AI的发展变成算力和数据量的竞赛。
进入2024年年末,随着各大AI独角兽公司发布的AI大模型能力提升幅度下降,特别是允许被使用的由人类贡献的数据已经挖掘殆尽,从而开始使用合成数据帮助训练,这让业界开始担心,即便算力允许,按照现在的技术路线,人类原生数据量是否能够满足训练出AGI通用人工智能的需求,如果开放更多的人类数据,需要从法律、伦理、人类风险等更高维度考量。
另一方面,越大的模型需要的运行成本越高,这会制约AI技术的应用规模,或者AI必须考虑是否有大规模市场需求或者战略需求,才有投入研发和运行的价值。所以大厂都在PK通用大模型、多模态大模型。
Q 平面设计师要失业了?
AI对影像制作领域的冲击开始于,2012年Google的吴恩达和Jef Dean使用1.6万个CPU训练了一个当时世界上最大的深度学习网络,指导计算机生成猫脸图片。

计算机生成猫脸图片
其后再到2022年7月Runway、CompVis、Stability AI首次发布StableDiffusion稳定扩散模型,8月22日正式开源,自此绘制图像不再是艺术家、设计师的专利,任何人都可以用文字引导计算机生成图像。
StableDiffusion解决两个痛点:1.生成的图像达到大众接受的程度;2.可以在个人PC上运行。关于Stable Diffusion模型生成图像的原理,因为过于晦涩难懂,通俗直观的定义可以称之为“特殊的预测模型”,扩散模型生成图像是通过分步预测噪声将正态分布的噪声图像逐渐去噪最终成为目标图像。所以我们AI工具里通常会有seed值影响预测的噪声,会有sampler指定去噪采样算法,会有steps去噪的步数。去噪步数越多,图像质量越高,消耗的算力多。
Stable Diffusion稳定扩散模型是AI图像生成开源模型的代表,同时开源社区发布的前端工具Stable Diffusion WebUI和ComfyUI让创作者从python命令行工作模式转变为可视化的通行界面,极大降低了AI模型使用的门槛。围绕这两款开源程序的各类图像生成优化控制工具也迅速发展,成为两大生态。后续发展出SDXL模型、Stable Diffusion3、FLUX、Stable Diffusion3.5等模型,在AI图像生成品质上日趋完善。ComfyUI以其节点编辑的灵活性在近半年赢得了更多重度专业用户的认可,甚至在其上发展出各种自动化工作流。
从2022年8月开始流传“平面设计师要失业了”,到现在2024年即将结束,我们可以看到一个现象,AI生成图像虽然有了非常大的进步,但也只是替代了一些简单的图像创作工作,而复杂且专业的图像制作任务需要非常复杂的流程和工具来完成,其难度不亚于PS,学习成本比PS也高很多,所以最终AI工具也分化为个人娱乐、常规辅助办公、专业级制作多种层次,最终专业的事情,还是要由专业的人用专业的工具来完成。
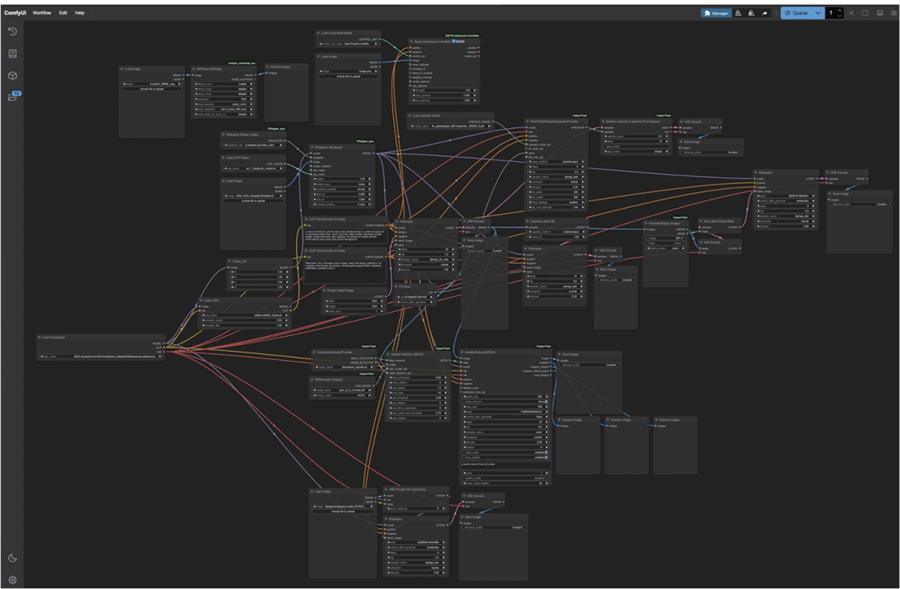
用AI完成专业任务所需要工具及流程
我相信未来针对很多通用场景会有强大的自动化AI工具,而这种自动化批量输出的内容很快会产生审美疲劳,就像现在大家都在研究如何去除AI生成图像的塑料味。
在开源的扩展工具中比较重要的有Controlnet模型工具,使得创作者通过Controlnet模型来影响Stable Diffusion模型生成的图像,可以影响其构图、角色动作、表情、风格、颜色等。

Controlnet模型工具
比如,2023年初AI扩散模型还不能自动生成文字,但是有了Controlnet的canny模型就可以用一张文字的图像作为参考图像,生成模型会以参考图像的文字轮廓为基础生成图像。
还有用文本提示词来描述生成图像的人物特征,结合Openpost模型提取参考图中人物的动作,文字提示和动作提示共同作用下会复合参考图中人物动作的新形象,如果使用视频逐帧作为参考,生成连续图像,可以做成新视频。
Q 做视频的也要失业了?
2023年初之际,影视制作圈的友人曾戏谑道:“从事平面工作的已然失业,从事视频工作的还会远吗?”彼时,众人并不忧心,缘由在于当时所生成的视频画面闪烁不定,且存在诸多逻辑舛误。因为此时AI是逐帧生成的画面,每个画面是随机预测噪声去噪后生成,即便通过辅助的控制工具也没办法让前后生成的图片保持连续统一。
2024年2月15日OpenAI的视频生成模型Sora横空出世。12月9日Sora正式开放使用基础功能与友商差异并不大,但有几个亮点:
1.REMIX模式可以对视频中的元素删除、替换、重构;
2.Recut模式可以指定某一帧进行扩展;
3.Storeboard用更直观的方式让创作者按照时间线控制生成视频。
官网新放出的样片质量在同业中可谓顶流,但依然有瑕疵,具体生成效果还要等待海外用户的深度评测。在视频生成赛道Runway、LumaAI以及国内的快手可灵、字节的即梦都早于Sora开放,收割了大批尝鲜用户。
2024年6月17日Runway发布了Gen-3Alpha视频生成模型,在保真度、一致性和运动方面有了重大改进,基本脱离玩具标签,可以作为生产力工具。
2024年9月19日快手发布可灵1.5模型在性能上有显著提升,画面稳定性和连续性有较大提升。视频生成质量提升很快,但依然会存在画面崩坏的概率,视频生成因为需要更强算力支持,目前除了少数开源视频生成模型可以本地部署使用外,上述视频生成工具都是平台运营订阅制。目前AI生成视频对于专业选手最实用的是生成小段素材应急。
Q 剪辑师要失业了?
AI应用的一个典型场景是AI智能短视频剪辑,目前AI智能剪辑的工具大概分两类,一类是基于传统非线性剪辑软件增加智能功能,例如剪映,提供智能脚本+素材混剪、智能字幕、智能朗读、特效模版等,非常接近于传统非线性编辑软件。
另一类是完全摈弃时间线,比如vizard.ai、Opus Clip、VEED等,由旁白驱动的智能剪辑云端工具,用户上传长视频,系统自动提取对白,然后根据用户设定的时长,通过AI分析字幕归纳多个主题,根据不同主题自动剪辑素材,还会识别主角画面,横屏转竖屏智能构图,一小时的长视频大概十分钟生成几十条短视频,还可以自动上字幕、加片尾等等。
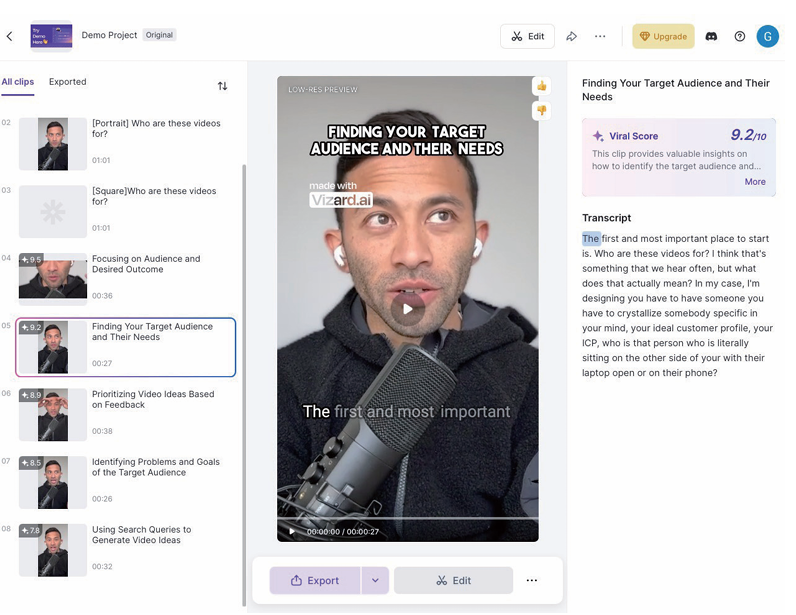
vizard.ai使用界面
这类工具让长视频转短视频更加自动化,对于拆条的工作会有很大帮助。当然其在使用中还是会出现纰漏,需要在线手动修复。这类工具极大提升了口播类的短视频产能,同时降低了成本,但同时也拉低了短视频的品质。各个工具背后AI算法能力直接决定了产出短视频的表达质量,因为视频内容是基于对字幕的提取再加工,对画面没有筛选能力或非常有限。此类工具适用于常规的口播类和快餐式播报内容,如果是复杂内容或是对镜头剪辑有较高要求的视频内容,还是要用传统剪辑工具和流程进行加工。
总结一下就是,专业的剪辑师应该不会失业,因为原来也是在做高要求的内容,而AI剪辑工具适用于轻量化的快餐式剪辑任务。当然或许以后AI可以深度理解画面,能洞察角色的情绪,能理解镜头的艺术表达,能够综合运用影视艺术语言创作出惊艳的影视作品。
Q 主持人要失业了?
在电商繁荣的当下,主播是刚需,根据《中国网络表演(直播与短视频)行业发展报告(2022-2023)》的数据显示,累计主播账号超1.5亿,短视频也有大量出镜主播。有需求的地方就会有供应,AI数字人迅速崛起,一种是2D方案,用真人动态影像为基础+程序驱动,基本固定视角。
另一种是3D方案,分为传统中之人驱动和AI驱动。从生产效率上,中之人驱动3D数字人因为动捕设备的轻量化,包括视频AI动补技术发展,使得其部署和使用日趋简便。
2D数字人、AI驱动的3D数字人前期部署包括配套知识库、预制规则、声音、形象、道具等多项准备工作,目前电商、播报类短视频是AI主播应用最广的领域,但观众的认知增长后,低劣数字人肯定会被嫌弃。数字人智力在于背后的AI能力,而AI能力由模型和算力决定,所以专业级数字人应用成本并不廉价,相比之下,真实的人类主播依然具备性价比优势。
Q 导演、编剧、制片人、演员、
配音、作曲会失业吗?
目前的观察,SDXL模型开源后,AI生成人物图像的能力得到大幅提升,之后不少摄影工作者开始用AI模特、AI换衣、AI换脸等工具用于生产电商物料,混迹江浙的服装模特确实受到不小冲击。
通过多位导演和编剧反馈的情况,在前期部分AI可以提供写作辅助和概念图创作辅助,基本无法提供最终交付版本,除非对稿子要求非常低。
制片人领域已经有高手开始使用Chat GPT、千问、Kimi等大模型的表格处理能力来辅助项目的器材、人员、片场、差旅等排期管理,但是准确度还有待观察。
演员需要关注传统演艺和运营数字分身,这将涉及很多新的商业规则和法律规则。目前炫酷的生成式AI数字人只存在于给投资人的PPT里,也没有能自由调度的高品质智能数字演员,所以演员这个职业尚未受到冲击。
AI音乐生成也是炒作得较热门,比如SUNO等工具,输入歌词和音乐风格就可以生产歌曲,也可以生产纯音乐,但是并不能完成复杂的音轨合成和专业调节。
对于专业影视流程的各个环节,AI的应用依然还是较为初级的阶段,没有哪个环节靠跟AI对话就可以完成。我们看到的“世界/国内首部AI电影”这类内容的品质与院线电影差距甚远,但未来基于AI生产逻辑的流程一定会越发成熟,任何技术发展的核心都离不开使用成本,AI也不例外。
总而言之,AI工具发展迅速,但近期有不少评测指出AI能力的增速在放缓。以近两年趋势看,AI工具在一些局部或单项功能上有突破,也确实创造出一些效果惊艳的内容。但是,AI工具想优雅地完成专业级的制作仍需面临巨大的挑战。
对于我们熟知的传统三维、剪辑合成工具,大厂也都在紧跟技术趋势,增加很多AI辅助功能。纯AI工具的赛道功能越专业,工具越复杂,学习门槛越高,最终还是专业的人在用。
回到开始的话题,如果有一天打通了碳基生命和硅基生命之间的连接,那么碳基生命和硅基生命将相互赋能,这将开启人类新纪元。比如,你只需要想就可以完成一个创作,也许是电影、小说或其他未知的形态。但有个前提,算力和电费不能太贵,否则一般人用不起。当下,我们仅需拥抱AI,坚持学习,依然可以惬意地用专业工具做专业的工作,让AI再飞一会儿。




























